SQL三部曲:你不需要ORM

曾經學習軟件開發的朋友,都應該在框架中,學過如何從資料庫讀取資料,而十之八九學到的方法,就是使用框架中的ORM程式庫。例如Ruby on Rails 內置了Active Record、Django內置了Django ORM、 Spring Boot則通常與 Hibernate一齊使用,C#則有一套本身的.Net Entity Framework。基本上通用的程式開發框架,都必然有自己的ORM程式庫。
ORM是甚麼呢?ORM全名是Object-Relational Mapping,中文是物件關係對映。顧名思義,就是將關聯式資料庫(Relational Database Management System)的資料,映射到物件(Object)之中,反之亦然。由於不少軟件工程師習慣使用物件導向程式語言(OO Languages),對物件導向概念如接口 (interface)、繼承(inheritance)等都瞭如指掌,而對SQL的關聯式用法卻不甚理解。本身關聯式資料庫(Relational Database)與物件導向的編程,先天 就有不少不契合的地方,電腦科學有一個專有名詞去形容關聯式資料庫與物件導向設計之間之不協調,也就是Object-relational impedance mismatch。為數不少的物件導向概念例如接口、繼承等,在資料庫的世界,完全沒有相對應的概念。 ORM的存在意義,就是為了撫平兩者中間的不協調,將資料庫中的資料,映射到記憶體的物件之中,而無需軟件工程師再煩惱。
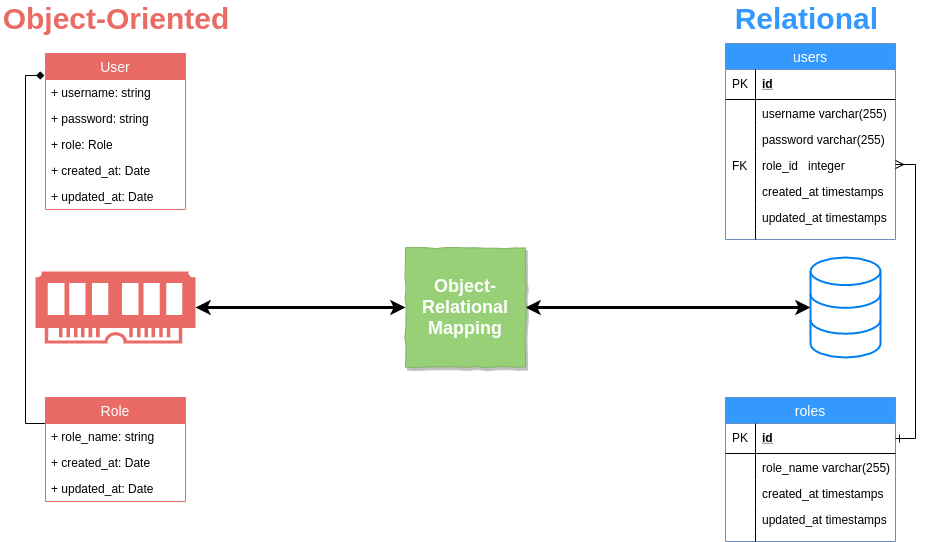
乍看之下,ORM很像是OO軟件工程師的福音,所以不少工程師一開始時使用都不亦樂乎,覺得似乎無須再受SQL之苦了。隨著時間推移,不少ORM的問題、壞處開始浮面......
以ORM生成SQL不比直接寫SQL簡單
ORM其中一個最重要的功能,就是為軟件工程師生成SQL,然後直接在資料庫運行。例如 JavaScript的ORM Sequelize,如果你使用Sequelize本身的API,就可以直接生成SQL再在資料庫運行。
Task.create({ title: 'foo', description: 'bar', deadline: new Date() }).then(
(task) => {
// you can now access the newly created task via the variable task
},
);
就會自動生成以下SQL。
INSERT INTO tasks (title,description,deadline) VALUES ('foo','bar','2019-10-22') RETURNING *;
簡單的SQL,ORM應付有餘,不過複雜的動作,ORM就無法推斷開發者的本意(intention)﹐因此往往生成比原本問題所需更複雜之SQL,效率上做成無謂浪費。
例如這個發表在StackOverflow的問題,原來的SQL算是不太複雜。
SELECT writers."writerName", posts."postTitle", posts."postDescription",
skillmatrix.*
FROM writers
INNER JOIN skillmatrix
ON writers."writerId" = skillmatrix."writerId"
INNER JOIN posts
ON skillmatrix."postId" = posts."postId"
ORDER BY writers."writerId", posts."postId"
結果 由sequelize生成的sql,成了以下這個樣子,比起手寫SQL select了更多資料,而inner JOIN的語句,也因設置失誤成為了
"skillmatrix"."skillMatrixId" = "writers"."writerId".
SELECT
"skillmatrix"."skillMatrixId",
"skillmatrix"."writerId",
"skillmatrix"."postId",
"skillmatrix"."writerSkill",
"writers"."writerId" AS "writers"."writerId",
"writers"."writerName" AS "writers"."writerName",
"posts"."postId" AS "posts"."postId",
"posts"."postTitle" AS "posts"."postTitle",
"posts"."postDescription" AS "posts"."postDescription",
"posts"."writerId" AS "posts"."writerId"
FROM
"skillmatrix" AS "skillmatrix"
INNER JOIN "writers" AS "writers" ON "skillmatrix"."skillMatrixId" = "writers"."writerId"
INNER JOIN "posts" AS "posts" ON "skillmatrix"."skillMatrixId" = "posts"."postId"
ORDER BY
"skillmatrix"."writerId" ASC,
"skillmatrix"."postId" ASC
而由題目中可見,開發者要設置的東西絕對不少,也要牢記不少一對多(One-to-many),多對一(Many-to-one)等關係,才能設置正確,否則生成之SQL就會出現錯誤。 那問題來了,到底是直接手寫SQL比較簡單?還是設置好sequelize,再運行API比較簡單呢?這一點確實見仁見智,以筆者為例,由於熟悉SQL的關係,絕對是手寫SQL比較簡單直接。 加上要除錯的時候,要直接為SQL除錯,絕對遠比隔著一層ORM要簡單得多,因為可以直接在資料庫運行該句SQL。
ORM不能夠完全取代SQL
大部份ORM的承諾都相類似:就是能夠解決你大部份的SQL需要,而無須你再為撰寫SQL而煩惱。基本SELECT、CREATE、 UPDATE、DELETE等普通語法,很多ORM程式庫都有良好支援,但讀過上一篇SQL二部曲的讀者都知道,其實SQL現今的功能遠比這些基礎語法要豐富。
就好像上一篇提過的WITH語句,市面絕大多數ORM都不能生成以下語句。
WITH RECURSIVE friends_network(id) AS (
SELECT people.* FROM people
INNER JOIN friends f on f.from_id = people.id
where people.name = 'eva'
UNION ALL
SELECT p.* FROM friends f
INNER JOIN people p on f.to_id = p.id
INNER JOIN friends_network fn on fn.id = f.from_id
) SELECT distinct * FROM friends_network order by id ;
不同的合計函數也是ORM的痛處。
select avg((config->>'age')::integer) as average_age, array_agg(people.name) as people_names from people group by config->>'age';
select avg((config->>'age')::integer) as average_age, json_agg(people.name) as people_names from people group by config->>'age';
select avg((config->>'age')::integer) as average_age, json_object_agg(people.name,people.*) as people_names from people group by config->>'age';
新的全文本搜索ORM就更不支援了。
SELECT * from people where to_tsvector('english',coalesce(name,'')) || to_tsvector('english',coalesce(description,'')) @@ plainto_tsquery('english','doe');
SELECT * from people where to_tsvector('english',coalesce(name,'')) || to_tsvector('english',coalesce(description,''))
@@ plainto_tsquery('english','hello');
通常ORM都附帶Fallback Mode,容許開發者直接運行Raw SQL,這不就是自打了嘴巴?開發者變相要同時對ORM及SQL熟練,才能夠隨心所欲的存取資料庫。在此情況下,ORM不只無法令開發者少寫程式碼,還要在兩種語言間轉換使用(Context Switch),筆者認為這樣還不如一開始就只寫SQL。反正SQL現今的功能齊全,很多以前只有ORM才有的功能,例如將結果變成JSON物件、串聯刪除(Cascade Delete)都在愈來愈多SQL資料庫中支援。
ORM之附加功能無須ORM框架
ORM通常都自帶了多種功能,包括上述的SQL生成功能(SQL generation)、數據庫演變(Database Migration)功能、連接池(Connection Pool)等。因此開發者通常將 ORM與其他功能一同運用,令管理資料庫更簡單。然而數據庫演變及連接池並非只有ORM框架才有的功能,例如Java的MyBatis,本身就是一個鼓勵開發者寫Raw SQL的框架,卻也同時自帶了連接池及數據庫演變的功能。JavaScript的SQL生成程式庫KnexJS,也自帶此類功能。因此要用這些看起來像是ORM才有的功能,其實根本不需要用ORM。
knex.schema.hasTable('users').then(function (exists) {
if (!exists) {
return knex.schema.createTable('users', function (t) {
t.increments('id').primary();
t.string('first_name', 100);
t.string('last_name', 100);
t.text('bio');
});
}
});
像以上一段的KnexJS代碼,正是運用了Knex自帶的數據庫演變功能。
現況
由以上幾點可見,ORM所能應用的範圍其實相當狹窄,很多問題其實都要以普通SQL解決。可惜現今不少初入行的軟件工程師都先學了ORM,卻沒有真正理解SQL背後的威力。正如前兩篇文所言,SQL由發明至今,已有四十多年的歷史,經過歲月洗禮,又加上了不少有用的功能,反之不少ORM程式庫可能都只有三數年的歷史,有這樣結果也不令人驚訝了。