SQL二部曲:五件事,你不知道SQL勝任有餘

上一篇文章講到了SQL的發展歷史,也提到了NoSQL的出現曾經為SQL資料庫帶來不少挑戰。正是這些挑戰,令現今SQL內置功能愈來愈豐富。近年SQL資料庫功能上大有進展,其中PostgreSQL功能日臻完善,運用PostgreSQL,連帶不少大家本以為只能運用NoSQL解決的問題,也可以輕鬆解決。 因此,本文主要會以PostgreSQL作舉例,當然以下很多功能在其他SQL實作如Oracle、SQL Server 、MySQL等都已逐漸支援,因此可看成是普遍SQL在不久將來廣泛支援的功能。
處理網絡狀數據(Working with Graph-based Data)
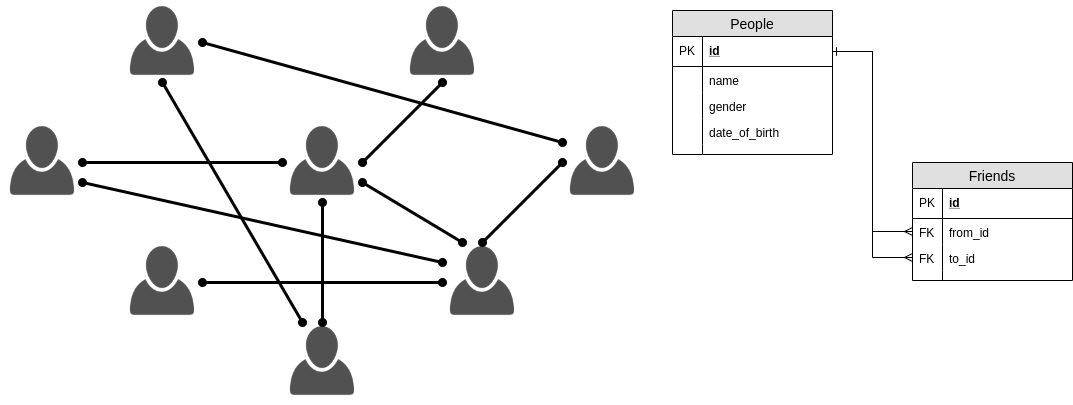
網絡狀數據對比起其他數據類型,數據間之聯繫更為複雜,社交網絡正是一個好例子。要儲存人際關係中的朋友關係,就必須將資料表達成網絡狀數據,因為每個人都有朋友,而他的朋友又會有其他朋友,其他朋友又再會有其他朋友。以SQL 去表示這個朋友之間的關係,就要用到兩個Table(表),分別是People及Friends﹐People所儲存的是個人資料,而Friends所儲存的是朋友的關係,是一個多對多關係(Many-to-Many relations)。
假如 其中people有六個人的數據:
select * from people;
id | name | gender | date_of_birth
----+---------+--------+---------------
1 | Alice | F | 1989-01-01
2 | Bob | M | 1988-01-01
3 | Charlie | M | 1987-01-01
4 | Doe | M | 1986-01-01
5 | eva | F | 1985-01-01
6 | flora | F | 1984-01-01
(6 rows)
而friends入面有以下數據:
select * from friends;
id | from_id | to_id
----+---------+-------
1 | 1 | 2
2 | 2 | 3
3 | 1 | 4
4 | 5 | 6
(4 rows)
由數據可見的是,Alice、Bob、Charlie、Doe 有朋友關係相連,而eva、flora互相是朋友,卻與其他四個人不相識。
問題來了,我們可以只寫一條SQL去將所有與Alice相關的人找出來呢?
大家如果不太熟悉SQL真正實力,可能會覺得這樣的Table結構很難寫SQL啊,如果要找出諸如朋友的朋友的朋友也是Mission Impossible。
其實現今SQL支援With語句,可以方便開發者直接撰寫一般資料表運算式(Common Table Expression)去表達複雜的語句。
尤其強大的是,可以運用WITH RECURSIVE直接編寫迴歸式(Recursive)語句!
因此要解決上述難題,以下SQL就可以一句KO。
WITH RECURSIVE friends_network(id) AS (
SELECT people.* FROM people
INNER JOIN friends f on f.from_id = people.id
where people.name = 'Alice'
UNION ALL
SELECT p.* FROM friends f
INNER JOIN people p on f.to_id = p.id
INNER JOIN friends_network fn on fn.id = f.from_id
) SELECT distinct * FROM friends_network order by id ;
id | name | gender | date_of_birth
----+---------+--------+---------------
1 | Alice | F | 1989-01-01
2 | Bob | M | 1988-01-01
3 | Charlie | M | 1987-01-01
4 | Doe | M | 1986-01-01
(4 rows)
要得到eva與其相關的人,只要將SQL中的Alice換為eva就可以了。
WITH RECURSIVE friends_network(id) AS (
SELECT people.* FROM people
INNER JOIN friends f on f.from_id = people.id
where people.name = 'eva'
UNION ALL
SELECT p.* FROM friends f
INNER JOIN people p on f.to_id = p.id
INNER JOIN friends_network fn on fn.id = f.from_id
) SELECT distinct * FROM friends_network order by id ;
id | name | gender | date_of_birth
----+-------+--------+---------------
5 | eva | F | 1985-01-01
6 | flora | F | 1984-01-01
相信結果出乎大家意料之外,不少人以為網絡狀數據只適合以圖資料庫(Graph Database)如Neo4j等去處理, 其實SQL要處理簡單的網絡狀數據,也依然是迎刃有餘。
儲存及搜尋JSON物件及數組(Store and search by JSON Object and Array)
NoSQL在2010前後其中一個興起的原因,是在於半結構化數據如JSON的廣泛使用,軟件開發者常常遇上一些棘手之情況,需要數據具靈活結構,但傳統的SQL Table結構卻難以容許這樣的彈性。重用上面之例子,例如我想為每個people的數據加入一個組態(Configuration)的欄位,也就是容許用戶自行填入個人自定義的設定,傳統SQL Table不容許在一個欄位(Column)有多層數據(Hierarchical Data),因此常用的做法是使用Entity–attribute–value model,將欄位的資料都儲存在Table之中。這個做法在運行效率上比傳統SQL Table要慢得多,也失去SQL非常有用之類型限制(Type Constraint)。因此MongoDB在2009年推出時,就正好解決了這個開發者的痛點。
PostgreSQL 本身由版本9.2開始支援直接儲存JSON數據類別。例如我想table people裏面儲存JSON到一個叫config的欄位,就可以將欄位定義為儲存數據jsonb(二進位制JSON)。
alter table people add column config jsonb;
ALTER TABLE
select * from people;
id | name | gender | date_of_birth | config
----+---------+--------+---------------+--------------------------------
2 | Bob | M | 1988-01-01 |
3 | Charlie | M | 1987-01-01 |
4 | Doe | M | 1986-01-01 |
5 | eva | F | 1985-01-01 |
6 | flora | F | 1984-01-01 |
1 | Alice | F | 1989-01-01 | {"age": 12, "role": "student"}
(6 rows)
以上的數據,使用平常的Update SQL,就可以直接將數據輸入。
update people set config = '{"age":12,"role":"student"}' where id = 1;
UPDATE 1
使用SELECT SQL,也可以基於JSON裏面的數據直接查詢。
select * from people where config->>'age' = '12';
id | name | gender | date_of_birth | config
----+-------+--------+---------------+--------------------------------
1 | Alice | F | 1989-01-01 | {"age": 12, "role": "student"}
(1 row)
甚至可以直接用JSON內之數據作出Group by的存取。
select config->>'age' as age, count(*) from people group by config->>'age';
age | count
-----+-------
| 5
12 | 1
(2 rows)
沒有JSON的行就當成就當是NULL處理。
因此,使用PostgreSQL已經可以同時處理結構化數據(Structured Data)及半結構化數據(Semi-Structured Data),既有傳統SQL的嚴謹,也有Document Database的靈活,可謂一舉兩得。
強大靈活的合計函數(Powerful aggregate function)
甚麼是合計函數(Aggregate Function)呢? 合計函數就是將多於一個的數據整合,成一個總結值(Summary Value),大家在Excel常用的SUM就是一個合計函數的例子,作用是將多於一個數值加在一起。上面用到的count也是一個合計函數的例子,是為了點算總數有多少。一般開發者使用SQL時,大多只會使用count及sum兩個合計函數。其實SQL本身還支援更多强大的合計函數,去完成更複雜的整合。
例如想將所有people的年齡取平均數,再將他們的名字連成一個數組(array),大家可能以為需要再編程去解決,其實光是使用SQL就綽綽有餘。
select avg((config->>'age')::integer) as average_age, array_agg(people.name) as people_names from people group by config->>'age';
average_age | people_names
---------------------+-----------------------------
| {Bob,Charlie,Doe,eva,flora}
12.0000000000000000 | {Alice}
(2 rows)
可以看見people_names成為了一個SQL裏的數組。那變成JSON array又可以嗎? 亦可,
select avg((config->>'age')::integer) as average_age, json_agg(people.name) as people_names from people group by config->>'age';
average_age | people_names
---------------------+-------------------------------------------
| ["Bob", "Charlie", "Doe", "eva", "flora"]
12.0000000000000000 | ["Alice"]
(2 rows)
people.names 變成了一個JSON Array,在JavaScript 再用JSON.parse就可直接讀取。如果你改為使用json_object_agg就更可選定鍵值組合(Key and value pair).
select avg((config->>'age')::integer) as average_age, json_object_agg(people.name,people.*) as people_names from people group by config->>'age';
average_age | people_names
---------------------+---------------------------------
| { "Bob" : {"id":2,"name":"Bob","gender":"M","date_of_birth":"1988-01-01","config":null}, "Charlie" : {"id":3,
"name":"Charlie","gender":"M","date_of_birth":"1987-01-01","config":null}, "Doe" : {"id":4,"name":"Doe",
"gender":"M","date_of_birth":"1986-01-01","config":null}, "eva" : {"id":5,"name":"eva","gender":"F",
"date_of_birth":"1985-01-01","config":null}, "flora" : {"id":6,"name":"flora","gender":"F",
"date_of_birth":"1984-01-01","config":null} }
12.0000000000000000 | { "Alice" : {"id":1,"name":"Alice","gender":"F","date_of_birth":"1989-01-01","config":{"age": 12, "role": "student"}} }
(2 rows)
整個JSON object亦可直接以SQL建構! 一條簡單的SQL,竟然能夠省卻了不少編程的功夫,在効能上也絕對比由自己再寫迴圈快了不少。
大家希望知道更多不同的合計函數的話,可於這個網址詳讀。
儲存鍵值數據(Storing Key and value pair)
講到儲存鍵值數據(Key-and-value-pair)的資料庫,大家第一時間想起的必然是Redis,畢竟Redis本身以Key-value store的功能而聞名,亦廣泛使用於快取的機制之上。
![]()
PostgreSQL呢?PostgreSQL也支援Hstore功能,本質上就是一個key-value store,而且與JSONB數據類型類似,基本上與其他SQL功能融合得非常好。 只要安裝了hstore,PostgreSQL 就可以直接將數據類型定義為hstore.
CREATE EXTENSION hstore; /*安裝hstore*/
alter table people add column additional_info hstore; /*加入 hstore數據欄位*/
然後使用內置的hstore函數,就可以將輸入的數據變成hstore。
Update people set additional_info = hstore(ARRAY[['profession','programmer']]) where id =2 ;
UPDATE 1
select * from people;
id | name | gender | date_of_birth | config | additional_info
----+---------+--------+---------------+--------------------------------+----------------------------
3 | Charlie | M | 1987-01-01 | |
4 | Doe | M | 1986-01-01 | |
5 | eva | F | 1985-01-01 | |
6 | flora | F | 1984-01-01 | |
1 | Alice | F | 1989-01-01 | {"age": 12, "role": "student"} |
2 | Bob | M | 1988-01-01 | | "profession"=>"programmer"
(6 rows)
要讀取這個鍵值,使用SELECT SQL也可以直接做到。
select * from people where additional_info -> 'profession' = 'programmer';
id | name | gender | date_of_birth | config | additional_info
----+------+--------+---------------+--------+----------------------------
2 | Bob | M | 1988-01-01 | | "profession"=>"programmer"
(1 row)
使用方法與JSON其實大同小異,不過因為效能轉為鍵值存取而設,當然效能上更好。
方便易用的全文本搜索(Full-text search)
與鍵值存取類似,提起全文本搜索(Full-text search),大家一定會想起Elastic Search,不過相對很少人知曉的是,PostgreSQL也原生支援了Full-text search,比平常慣用的like '%something%'要強大得多,也會將文字首先處理,去掉文尾,再作文本搜索。
假如我新加一個欄位叫description。裏面放了每個人的自我介紹。
select name,gender,date_of_birth,description from people;
name | gender | date_of_birth | description
---------+--------+---------------+----------------------------------------
Bob | M | 1988-01-01 |
Charlie | M | 1987-01-01 | Hello, my name is Charlie
Doe | M | 1986-01-01 | I am a programmer
eva | F | 1985-01-01 | Hello, this is eva
flora | F | 1984-01-01 | Hi guys, I am flora
Alice | F | 1989-01-01 | Hi everyone , I am a software engineer
(6 rows)
我們想建立一個搜尋器,可以同時搜尋name及description。這個時候Full-text-search就大派用場。
SELECT * from people where to_tsvector('english',coalesce(name,'')) || to_tsvector('english',coalesce(description,'')) @@ plainto_tsquery('english','doe');
id | name | gender | date_of_birth | config | additional_info | description
----+------+--------+---------------+--------+-----------------+-------------------
4 | Doe | M | 1986-01-01 | | | I am a programmer
(1 row)
SELECT * from people where to_tsvector('english',coalesce(name,'')) || to_tsvector('english',coalesce(description,''))
@@ plainto_tsquery('english','hello');
id | name | gender | date_of_birth | config | additional_info | description
----+---------+--------+---------------+--------+-----------------+---------------------------
3 | Charlie | M | 1987-01-01 | | | Hello, my name is Charlie
5 | eva | F | 1985-01-01 | | | Hello, this is eva
(2 rows)
這個做法由於本身已內置於PostgreSQL之內,無須再為安裝ElasticSearch或為ElasticSearch同步數據而煩惱,如果數據量不是天文數字, 絕對可以考慮這個做法。
總結
以上五個功能,在傳統的SQL資料庫上都無法輕易解決,因此催生了解決相應問題的NoSQL資料庫,及至現在不同的SQL資料庫都開始將這些功能重新整合, 又再造就了新一代的SQL資料庫了。