HTTP:互聯網的共同語言

互聯網的共同人類語言是甚麼呢?答案是英文,根據維基百科,世界上有五成四的網站都是以英文寫成,另外的四成六則以其他世界各地的語言寫成,所以說互聯網上的用家(即是各位)主要使用英文溝通也不為過。可是大家細想一下,互聯網上的電腦,又是怎樣互相溝通的呢?當你鍵入
https://www.google.com,為何遠在千里之外的Google伺服器,能夠與你桌上的手提電腦裏的Google Chrome溝通呢?這一切,要由互聯網誕生之初講起。

互聯網之誕生
互聯網基於不同年代發明的科技所運作,現在大家早已習慣的光纖,是由光纖之父高錕於1966年最早提出光纖可以作為長距離高速通信的媒介,爾後有其他科學家再實作出可以傳輸資訊的光纖;而最早將多部電腦作為網絡連接的實驗,是美國於六零年代研發的ARPA網,及至七十年代已有歐洲的電腦包括在網絡中,大家可能聽過的TCP/IP,正正是由ARPA網於1983年所發展出來。最後一部份,由添‧柏納斯‧李發明了HTML、HTTP。最早的互聯網就終告成形。以下是一張顯示現代互聯網所基於的協定。
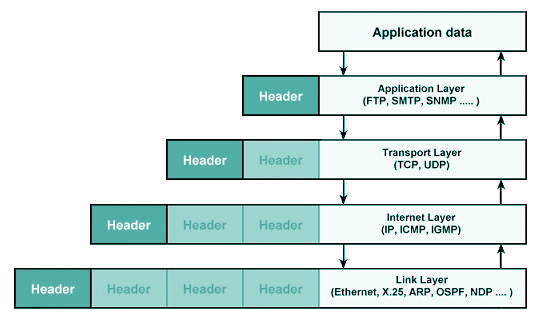
上圖所顯示的,其實不同協定所堆疊出來的TCP/IP模型。協定(Protocol)就是一個通訊中兩方面都能理解的溝通型式,最形像化的例子,就
是兩方面中間的共同語言,正因整個模型是互聯網運作之基本組成部份,因此又名作互聯網協議(Internet Suite)。
TCP/IP其實包括TCP、IP兩種協定,分別份屬傳輸層(Transport Layer)、網絡層(Internet Layer),HTTP(超文本傳輸協定)。則屬於上面應用層(Application Layer)。
科技詞語解釋: 以上各種不同的層,概念相當抽象,即使大家直接閱讀維基百科也不易理解,理解的最佳方法,是以大家每季都要收到的水費單作為例子。
- 應用層(Application Layer): 應用層就是當水務局計算了陳大文先生今季的水費,將水費單郵寄給陳大文先生。
- 傳輸層(Transport Layer): 傳輸層就是郵差,專責將水務局的信件送到陳大文家中信箱。
- 網絡層(Internet Layer): 網絡層就是郵寄地址,信件上必須寫好郵寄地址,才能準確送達。
- 連結層(Link Layer): 連結層指的就是街道上的郵箱、陳大文大廈的郵箱,沒有郵箱,陳大文也不能收到水費單了。
由此例子可見,應用層關注的是最抽象將水費單送到陳大文手上,不會關心陳大文家中是否有郵箱。傳輸層也只會送信,信中內容,不管是律師信還是水費單,郵差也不在乎。
網絡層着重的是地址清晰及唯一,因此地址要寫成像荃灣海盛路11號One Midtown 27樓15-16室,不可以只寫成荃灣,不然信就送不到陳大文手上。連結層着重的
是硬件上是否無礙,郵箱爛了,就無法寄信。 每上一層,愈抽象;每下一層,愈具體。
愈抽象,則愈接近日常應用;愈具體,平時就不為人所見(你對上一次看過郵差正好派信給你是何時?)
要理解這個複雜的模型,由最上層的HTTP開始理解,就再好不過。TCP/IP將留待以後解釋。
HTTP
比較下面的傳輸層、網絡層,HTTP算是相當廣為人知,大家上網的網址前,都有http://或是https://的字樣,例如大家常去的https://www.google.com前面就有https://。HTTP的全名,是Hypertext Transfer Protocol,中文就是超文本傳輸協定。超文本的意思,就是指HTML,因為HTML的全名就是Hypertext Markup Language(超文本標記語言),而整個HTTP的運作方式都為了從伺服器將HTML及其他資料傳輸到瀏覽器之內,因此事如其名,是有其因由。
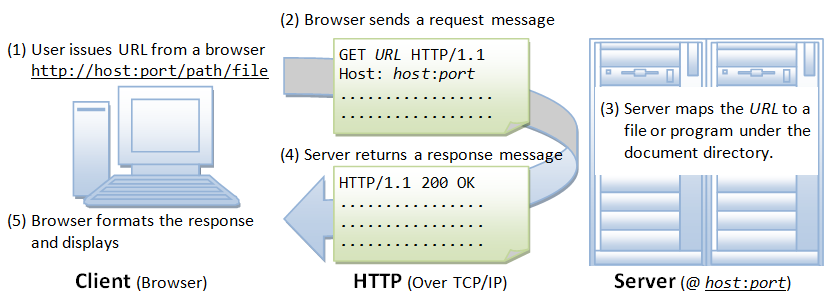
HTTP的運作方法並不複雜,上圖就將整個過程,由輸入網址開始,直至網站就緒,分為五大部份
1. 用戶於瀏覽器鍵入URL(全名是Uniform Resource Locator),通常URL都會有以下的格式
http://host:port/path/file
http://tecky.io:1234/
所謂Host(主機)就像大廈名,port就像單位名稱,一棟大廈可以有很多單位,同理一部主機也有很多不同的port,最常見的port就是80。
平常大家上網的時候,很少會真正看見:port的身影,如果沒有寫下像上邊tecky.io:1234的例子一樣寫下port,瀏覽器就會預設為80。
而對於https://開頭的網站來說,port就是443。
2. 瀏覽器送出一個HTTP請求(HTTP Request)
HTTP請求的格式非常簡單,因為HTTP是一個文字為主(Text Based)的協定,以下是一個HTTP請求的例子。
GET / HTTP/1.1
Host: www.google.com
User-Agent: curl/7.58.0
Accept: */* en-US,en;q=0.9,zh-TW;q=0.8,zh;q=0.7
請求(Request)包含了瀏覽器傳送給伺服器的資訊,元數據(Metadata)例如語言、日期等則會放到HTTP標頭(Header)之中,而其他資訊則會放到
HTTP正文(Body)之中。當大家上載圖片時,圖片的內容就是放在正文之中。而大家經常於不同網站登入登出,該登入之狀態則是由一個
叫cookie的標頭所儲存,這正正是為何於公共地方使用無加密Wifi不安全,因為標頭資料可以輕易被竊取。
3. 伺服器將URL映射到伺服器程式
伺服器程式(Server Software)與伺服器(Server)是常常被混用的兩個詞語,一般來說,伺服器指的是硬件,而伺服器程式指的就是在硬件運行專為了回答HTTP請求的軟件,因為此程式設計師常常會用Server一詞借代Server Software。PHP、NodeJS、Java、Python都是編寫伺服器程式常用的程式語言。而編寫此類軟件時,也常常需要不同的框架,較受歡迎的有:Express、Laravel、Django等。
伺服器程式普遍都會接駁到資料庫,以儲存用戶之資料。
4. 伺服器傳回一個HTTP答覆
伺服器根據請求內容的不同,回覆不同的HTTP答覆(Response),像請求一樣,HTTP答覆一樣有正文(Body)及標頭(Header)之分。通常網站會將內容放到正文之內。而同樣屬於元數據的資訊則會放到標頭之中。對應上面向Google的請求,以下正是由Google 伺服器而來的答覆:
HTTP/1.1 200 OK
Date: Mon, 25 Feb 2019 03:03:15 GMT
Expires: -1
Cache-Control: private, max-age=0
Content-Type: text/html; charset=ISO-8859-1
P3P: CP="This is not a P3P policy! See g.co/p3phelp for more info."
Server: gws
X-XSS-Protection: 1; mode=block
X-Frame-Options: SAMEORIGIN
Accept-Ranges: none
Vary: Accept-Encoding
Transfer-Encoding: chunked
<!doctype html><html ...
答覆上面的是標頭,以下的是正文,正文由於實在太長,故此省略從簡,正文的內容,正是以HTML格式寫成。
5. 瀏覽器讀取答覆,顯示網站
瀏覽器讀取了答覆,根據HTML的規則,將整個網站顯示出來,就成了大家習以為常的Google 搜尋器版面。
因此,簡簡單單的顯示一個網頁,確實蘊含着過去幾十年人類資訊科技發展的結晶,殊不簡單。
HTTP的版本
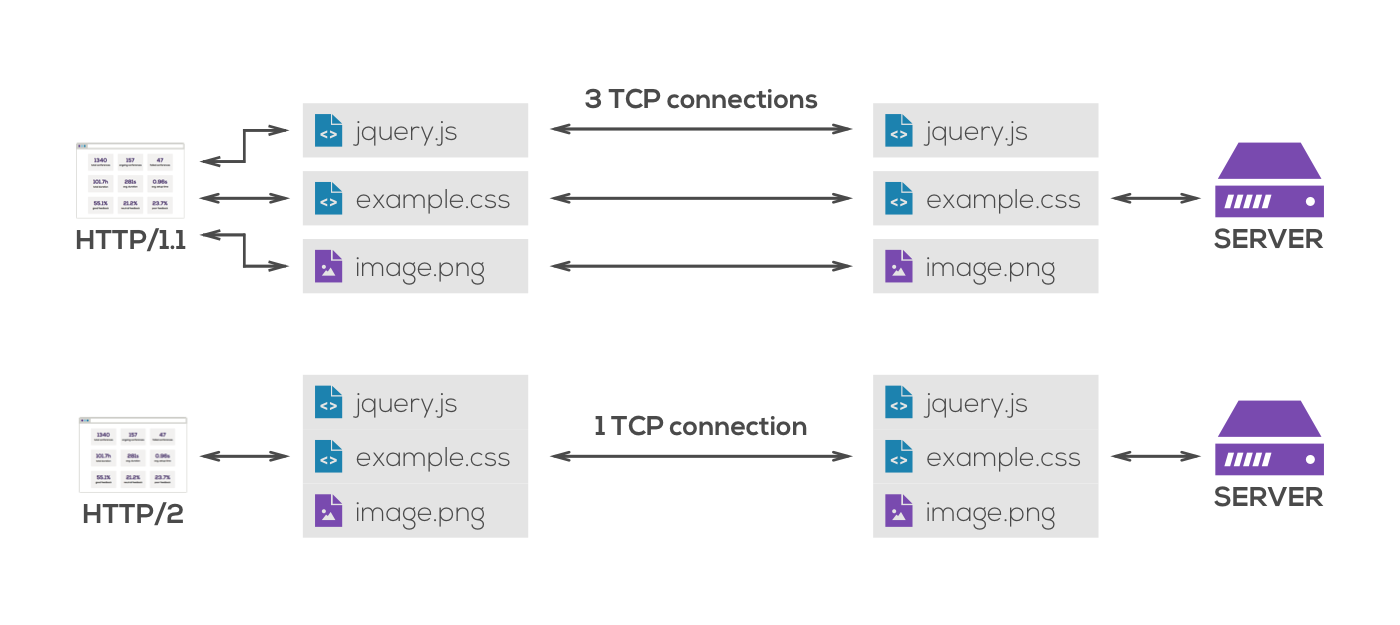
有甚麼比理解HTTP的運作方式更困難?就是要理解三個HTTP的運作方式。HTTP最常用的版本是HTTP/1.1也就是1.1版本,於1999年由互聯網協會所公佈。而及至2014年,又再發佈了HTTP/2作為最新的實作標準,要發佈新的標準,是因為現今的網站,與上世紀九十年代,已大相逕庭。HTTP/2的製定主要為了改善大網站載入速度較慢的問題,減少所需的請求數,節省載入時間,從而改善用戶體驗。而很多現有支援HTTP/2的伺服器及客戶端都原生支援加密通信,令互聯網更安全。
HTTP/2才支援了不久,出現在大家視野的,還有HTTP/3,HTTP/3最早由Google的工程師所開發,希望更進一步改善傳輸速度及於協定中提供安全保護。在2015年就已經開始了標準化的工作。
總結
科技的發展,除了硬件愈來愈快,體積愈來愈小,效率愈來愈高之外,常常被人忽略的,其實是範式轉移(Paradigm Shift),HTTP的發展,正是隨著大家對網上應用(Web Application)的理解日益進步,才有今日的成果。大家下次瀏覽你最愛的網站,不妨停下來,想一想沒有HTTP、互聯網的世界,會是多麼的不同。