非結構化數據

近年數據科學及人工智能發展迅速,大眾開始對數據(Data)有很大興趣,甚至有「數據是未來的石油」(Data is the new oil)的講法。很容易會聽到如大數據(Big Data)、數據導向決策(Data Driven Decision)、數據化組織(Data Organization)等等與數據相關的詞語,其中重點,不外乎都是如何運用已儲存的數據,通過數據處理及數據分析,從而得出結論,幫助決策。筆者今日希望談談的,是另一個技術用語,與大數據一詞經常一齊出現,就是非結構化數據(Unstructured Data)。
何謂數據
要理解非結構化數據,要先理解何謂數據,廣義上的數據通常指的是原數據(Raw Data),是我們為了記錄事物而製造出來,因此要定義數據,筆者會用以下的定義。
數據本質上是紀錄(Record),是狀態的紀錄(Record of states),通常專指未經處理的原數據(Raw Data)。
記錄的形式可以包羅萬有、層出不窮,一個原始人結的繩結是數據;一本寫在竹簡上的書是數據;一個Excel檔案也是數據。資訊科技的高速發展,令我們可以儲存及記錄大量數據。由數據開始,人類可以掫取資訊(Information),歸納為知識(Knowledge),內化成智慧(Wisdom)。
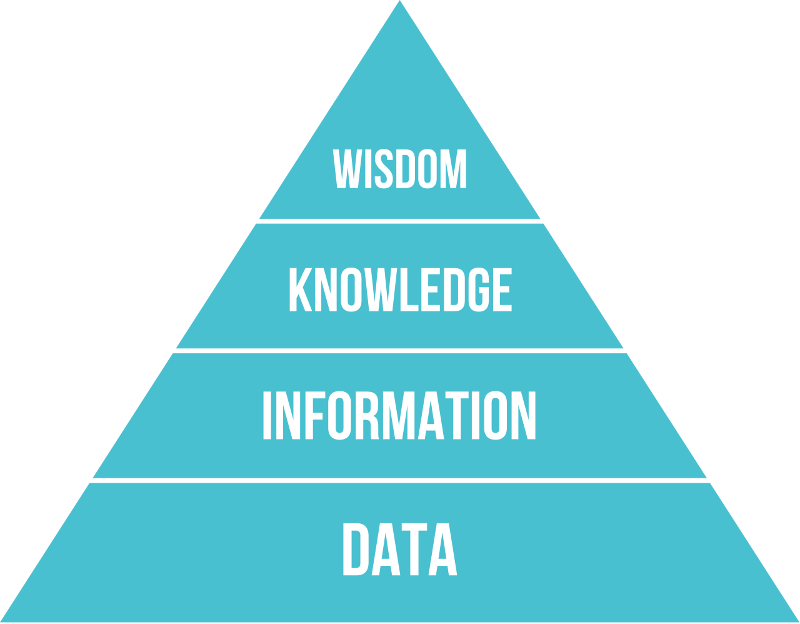
所以數據是分析、學習的基礎,沒有數據,則無法從中掫取資訊,知識就更不可能由其中歸納而成。因此現今對數據的重視,最終目的,就在於希望由分析原數據,得到未知的見解(insight)。
結構化
只是有數據,仍是不夠,我們還需要將數據以結構化(Structured)的方式儲存,才能加以利用。試分析以下兩個情況:
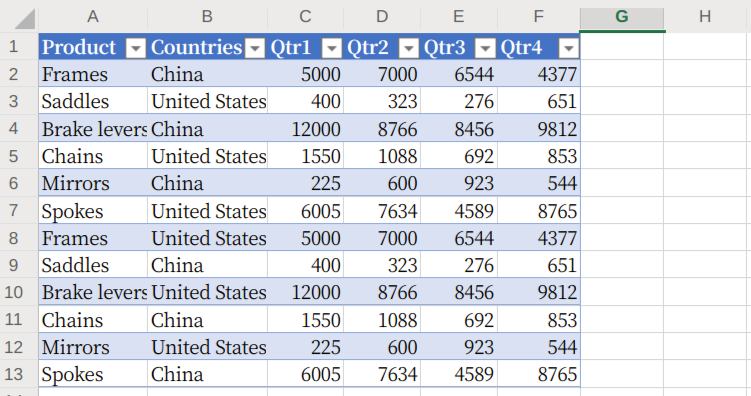
- 將銷售數據變成如下圖Excel欄及列的形式,分門別類處理好。
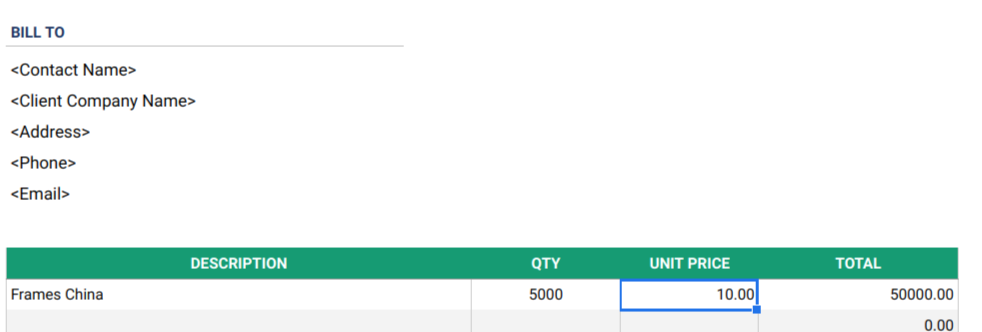
- 收集好每一張銷售發票及銀行月結單,再作統計
要作銷售額統計,兩者較為容易呢?理所當然是前者。
分野原因何在?最關鍵的原因,在於數據是否已經結構化,Excel的欄及列有明顯數據結構:Product、Countries、Qtr1、Qtr2都是早已定義好的
標頭,要做的只是將不正確的數據清理好,就可以開始分析數據。
相反,銷售發票通常容許較多彈性,沒有統一的填寫方法,例如上圖description中,容許使用者任意填寫任何文字,就稱不上是結構化數據,因為根本沒有一個統一的格式,在分析上就會遇到很多困難。亦正是如此,很多公司都利用系統生成銷售發票,正是為了規範格式。
簡而言之,結構化數據方便處理,也更容易分析,將數據儲存成結構化的格式,有明顯的好處。
那為何非結構化數據成為討論熱點?
這就奇怪了,既然結構化的數據在處理遠比非結構化數據更為簡單,為何近年的討論都集中在非結構化數據之上呢? 箇中原因其實很簡單,結構化數據在過去數十年間,早已是數據分析的中流砥柱,要分析結構化數據,甚至有一個專有的範疇:商業智能(Business Intelligence)就正正是專為了分析結構化數據而設,微軟近年開發的商業智能工具PowerBI就正正是其中最好的例子。
相反,非結構化數據卻被長期忽略,大家細想日常工作所傳送的電郵、收取的表格、Facebook上的影片等,都是數據的一部份,然而由於分析難度很大,通常在分析數據時,都會盡量避免處理這些數據,以節省人力物力。如分析大量Facebook影片的內容,不以人力逐一觀看,就只有運用現今深度學習的算法,如圖像辨識(Image Recognition)等,才能掫取有用的數據。正因如此,很多可能有用的數據就這樣被埋沒了。
結構化數據三層級
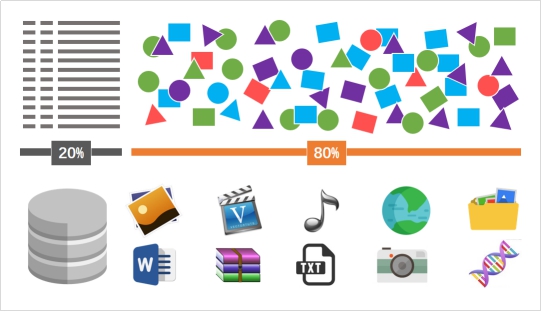
除了上述的例,結構化和非結構化數據還有其他例子嗎? 下圖綜合了三種不同結構化程度的數據:

由上圖可見,圖片、影片、即時對話內容、錄音、手寫資料、電郵、二進位檔等都是非結構化數據的最佳例子。而關聯式資料庫、CSV檔、Excel檔案等則是結構化數據的例子,能夠使用傳統的數據分析工具去處理及理解。 結構化數據及非結構化數據中間,還有一個灰色地帶,也就是半結構化數據,半結構化數據包含了常用傳輸格式: XML、JSON、YAML等,因為這些格式有一定的格式架構,例如JSON只支援數組(Array)、物件(Object)、字串(String)等常用的數據型別,但又不會像關聯式資料庫(RDBMS)般需要一個既定的型式,因此在編程中常常用作傳輸、儲存數據。NoSQL中使用的,也常常是半結構化數據,例如MongoDB就是儲存了JSON格式的數據。
有估計都認為,結構化數據及半結構化數據其實只佔了總體數據的百分之二十,剩餘的百分之八十都是屬於非結構化數據的領域。 日常工作、瀏覽網頁,用戶時刻都製造了許多數據,而這些數據,很多就屬於非結構化數據。
非結構化與數據科學
正因大部份的數據本質上都是非結構化,因此在大數據時代的今日,要分析、處理、圖像化非結構化數據,就使數據科學(Data Science)成為了一門顯學。不同機構及公司都因此爭相聘請數據科學的人材,去處理這個長期忽略的「大多數」。無意之間也令大眾衍生了一種誤解:以為結構化數據與非結構化數據中間有一條楚河漢界,又或是以為非結構化數據是一個新的數據格式。實際上兩者都是由來已久,只是近年技術發展迅速,出現了不少大數據的工具,例如Apache Spark、Kafka、Hadoop等,數據處理工具Pandas等亦漸成主流,才令非結構化數據走到了舞台的中心位置。